2015 年 8 月开始,Facebook 允许用户进行视频和语音直播,这篇文章描述 Facebook 的工程师是如何在从零开始在 8个月的时间里搭建这个有过亿活跃用户的平台。
目录
- 高层次架构
- 高并发挑战
- 传输协议以及编码
- 3.1 协议比较
- 3.2 RTMPS 协议介绍
- 3.3 编码属性
- 数据获取以及处理
- 4.1 直播流程
- 4.2 播放流程
- 4.3 HTTP 流媒体 (MPEG-DASH)
- 可靠性挑战
- 5.1 网络因素
- 5.2 惊群效应
- 学到的经验
(如何选择合适的 POP,RTMPS 使用 push 模型,为什么使用MPEG-DASH )
1. 高层次架构
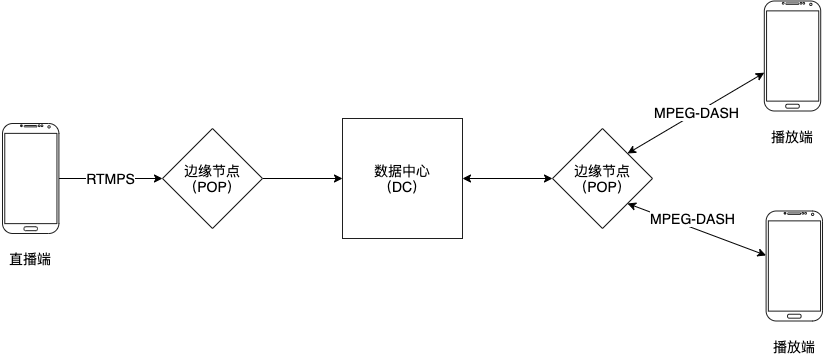
- 直播端使用 RTMPS 协议发送直播数据到边缘节点(POP)
- POP 发送数据到数据中心(DC)
- DC 将数据编码成不同的清晰度并进行持久化存储
- 播放端通过 MPEG-DASH / RTMPS 协议接收直播数据
2. 高并发挑战
- 直播数据是实时生成的,所有不能够进行预缓存
- 直播随时会发生,所以无法通过预计直播数量来提前分配资源
- 无法预计某个直播会不会观看者暴增
3. 传输协议以及编码
我们需要根据以下 4个 方面选择传输协议以及编码。
-
上线时间
Facebook live 从黑客马拉松到正式上线用了 4个月时间,覆盖到所有用户一共耗时 8个月。在这么紧的上线时间要求下,我们需要用到 Facebook 提供的所有优势,包括网络,公共模块等。
-
网络兼容
Facebook 网络架构是基于 TCP 协议的,所以我们的传输协议最好也是基于 TCP。
-
点对点延迟
低延迟对直播非常重要,一旦延迟高,直播端与播放端的交互性就会降低,我们希望保证延迟在 30秒 以内,理想情况是在几秒内。
-
应用大小
Facebook live 是内嵌在 Facebook 应用中,我们有 500 kb 的额度用作开发。
3.1 协议比较
| 协议 | 上线时间 | 网络兼容 | 端对端延迟 | 应用大小 | 问题 |
|---|---|---|---|---|---|
| WebRTC | ✗ | Webrtc 基于 UDP,和 Facebook 的网络架构不兼容 | |||
| HTTP Upload | ✗ | 会导致网络高延迟 | |||
| Custom Protocol | ✗ | 工程师需要实现自己的客户端与服务端的库,无法按时上线 | |||
| Proprietary | ✗ | 需要几兆的空间,超出额度 | |||
| RTMPS | ✔ | ✔ | ✔ | ✔ |
3.2 RTMPS 协议介绍
RTMPS 协议就是为视频直播设置的,1) 它能够保证低延迟。2) 它在工业上已经被广泛应用,所以能够重用已有的客户端和服务端的库。3) 它基于 TCP 协议能够与 Facebook 的网络架构兼容。4) 应用大小在 100k 左右。
3.3 编码属性
| 类型 | 数值 |
|---|---|
| 长宽比 | 1 比 1 |
| 解析度 | 400x400 和 720x720. 如果用户网络不好会自动转换成低分辨率 |
| 音频编码 | AAC 64KBIT |
| 视频编码 | H264 500KBIT 1MBIT |
4. 数据获取以及处理
4.1 直播流程
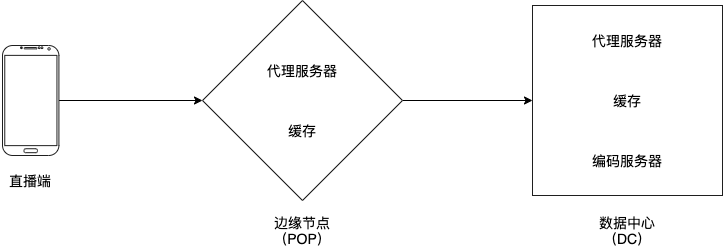
- 直播端使用 RTMPS 协议发送直播流数据到 POP 内的随机一个代理服务器
- 代理服务器发送直播流数据到数据中心
- 数据中心的代理服务器使用直播 id 与一致性哈希算法发送直播数据到合适的编码服务器,
- 编码服务器有几项职责:
- 4.1 验证直播数据的格式是否正确。
- 4.2 关联直播 id 以及编码服务器,保证即使连接中断,在重新连接的时候依然能够连接到相同的编码服务器。
- 4.3 使用直播数据编码成不同解析度的输出数据。
- 4.4 使用 DASH 协议输出数据。
- 4.5 把输出数据进行持久化存储。
4.2 播放流程
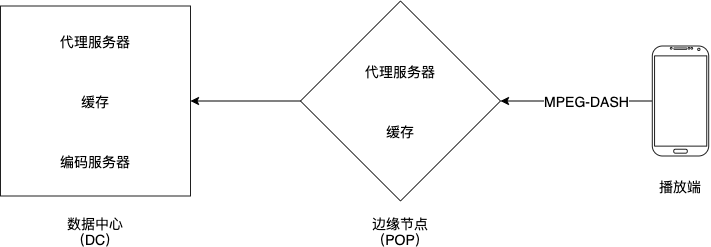
- 播放端使用 HTTP DASH 协议向 POP 请求直播数据
- POP 里面的代理服务器会检查数据是否已经在 POP 的缓存内。如果是的话,缓存会返回数据给播放端,否则,代理服务器会向 DC 请求直播数据
- DC 内的代理服务器会检查数据是否在 DC 的缓存内,如果是的话,缓存会返回数据给 POP,并更新 POP 的缓存,再返回给播放端。不是的话,代理服务器会使用一致性哈希算法向对应的编码服务器请求数据,并更新 DC 的缓存,返回到 POP,再返回到播放端。
4.3 HTTP 流媒体 (MPEG-DASH)
5. 可靠性挑战
5.1 网络因素

- 根据网络连接速度来自动调整视频质量
- 使用短时间的数据缓存来解决直播端不稳定,瞬间断线的问题
- 根据网络质量自动降级为音频直播以及播放
5.2 惊群效应
- 当多个播放端向同一个 POP 请求直播数据的时候,如果数据不在缓存中,这时候只有一个请求 A 会到 DC 中请求数据,其他请求会等待结果。但是如果请求 A 超时没有返回数据的话,所有请求会一起向 DC 访问数据,这时候就会加大 DC 的压力。解决这个问题的方法就是通过实际的情况来调整请求超时的时间。这个时间如果太长的话会带来直播的延迟,太短的话会经常触发惊群效应。
6. 学到的经验
- 大型项目都是从小开始的
- 开发的时候要考虑以及适配不同的网络条件
- 可用性以及扩展性需要在架构设计的时候开始规划,而不是后来才加上去
- 热点服务器以及惊群效应在许多组件中都可能发生
- 要为内存耗尽,服务器耗尽,带宽耗尽做好计划
- 开发大型项目需要做出妥协
- 保证架构的灵活度,方便进行下阶段的扩展